La revue de web de Kat
La directive européenne sur les liens hypertextes pourrait amener le géant à arrêter Google Actualités.
(CCM) — L'arrêt de Google Actualités en Europe est un scénario actuellement à l'étude chez Google. C'est en tout cas ce qu'affirme un vice-président du géant californien dans un entretien au Guardian. Si la taxe sur les liens hypertextes est votée dans le cadre de la directive européenne sur le droit d'auteur, ce pourrait être la fin de Google Actualités.
L'article qui pose problème dans la directive sur le droit d'auteur est l'article 11, qui prévoit de taxer les liens sortants vers les médias et sites de presse. Depuis le début des discussions, le projet est controversé. D'un côté, les associations de défense des libertés numériques lui reprochent de saper la base de ce qui fait le web : les liens. De l'autre, les géants américains ne veulent pas entendre parler d'une obligation de rémunérer les producteurs des contenus publiés sur Internet alors que leurs services sont gratuits.
D'après le vice-président de Google rattaché aux médias, Google Actualités n'utilise pas directement le contenu créé par les médias en ligne. L'application mobile et le site web du service ne sont que des intermédiaires entre les internautes et les sites de presse. Google Actualités ne fait que rediriger l'audience, et il le fait gratuitement, pour les éditeurs comme pour les internautes.
Reste que la Commission Européenne a bien l'intention de réformer les pratiques du droit d'auteur pour les adapter aux usages numériques du XXIe siècle. La monétisation des liens hypertextes est défendue par les autorités européennes, mais également par les agences de presse. Celles-ci y voient la possibilité de rémunérer la production de leurs fils d'actualités. Jusqu'à maintenant, la plupart des services d'agrégation de contenus comme Google Actualités référencent leurs articles sans contrepartie. En 2016, une étude de la Commission Européenne montrait que 47 % des internautes s'informent sans cliquer sur un seul lien.
En 2014, l'Espagne avait adopté une loi similaire prévoyant de taxer les clics sur les liens hypertexte. Immédiatement, le service Google Actualités avait fermé en Espagne. C'est ce scénario que Google étudie, mais à l'échelle européenne cette fois. Pour l'écosystème des éditeurs de sites d'informations, ce serait une véritable révolution.


La sophistication des logiciels de retouche d’images est telle qu’il est parfois difficile de déceler les tentatives de falsification des photos.
Les trucages sont la plupart du temps grossiers, mais ce n’est pas toujours le cas.
Pour démêler le vrai du faux et percer à jour les prises de vue truquées, faites appel à Forensically, un outil en ligne gratuit et performant.
Repérez les éléments clonés
L’application Forensically est accessible depuis n’importe quel navigateur Web.
Cliquez sur Open File, sélectionnez votre image et importez-la en cliquant sur le bouton Ouvrir. Elle s’affiche dans la fenêtre centrale.
Pour vérifier si des parties du cliché n’ont pas été clonées, choisissez l’intitulé Clone Detection.
Après un scan, des traits roses apparaissent indiquant les éléments susceptibles d’avoir été manipulés. Augmentez les valeurs des curseurs Minimal Similarily, Minimal Cluster Size et Block Size afin d’affiner l’analyse.
Recherchez les traces de manipulations
Pour déceler les éventuelles traces de trucage ou de montage, sélectionnez l’onglet Magnifier. Positionnez alors le curseur de zoom sur 8. Déroulez le menu Enhancement, puis cliquez sur l’option Auto Contrast by Channel.
Passez ensuite le curseur de votre souris sur les parties de l’image signalées par l’outil Clone Detection ainsi que sur celles qui vous semblent présenter des défauts de perspective ou des aberrations colorimétriques. Le zoom accentue les imperfections nées d’un montage imparfait.
Détectez les artefacts
Cliquez sur la commande Error Level Analysis afin de repérer les artefacts, autrement dit les éléments ajoutés à l’image originale. L’écran devient noir.
Positionnez le curseur JPG Quality sur 100, puis minorez cette valeur cran par cran au moyen de la flèche gauche du clavier.
Si des tâches apparaissent, cela signifie très probablement que le cliché a été trafiqué par endroits, la qualité de la compression JPEG n’étant pas identique en tout point de la photo. Affinez la détection en continuant de baisser le niveau de qualité.
Détaillez les propriétés de la prise de vue
Un autre moyen de savoir si l’image a été modifiée consiste à cliquer sur Meta Data afin d’accéder à ses propriétés.
Comparez les dates indiquées sur les lignes DateTimeOriginal et ModifyDate. Si elles sont dissemblables, il y a fort à parier que la photo a été retouchée.
Le nom du logiciel ayant servi aux manipulations est parfois mentionné dans la section Software.
Il se peut aussi que le cliché ait été géolocalisé. Dans ce cas, le menu Geo Tags est disponible et affiche une carte de l’endroit où la photo a été prise.
Avec la directive sur droits d’auteur, les eurodéputés et les lobbys de la presse semblent s’être lancés dans une surenchère réglementaire qui, si elle n’était pas mortifère, en serait comique.
A l’origine, l’objectif était de contraindre les plateformes et sites internet relayant l’information produite par les éditeurs de presse à négocier avec ces-derniers afin de rémunérer l’utilisation de leur contenu. Si, en apparence, l’idée est parfaitement défendable, son application relève d’importants effets pervers.
Tout d’abord, la directive précise que les plateformes et sites auront l’obligation de vérifier les droits d’auteur de tout ce qui sera diffusé et partagé sur leurs utilisateurs, ce qui les rendre de facto responsable de toute violation des droits d’auteur des éditeurs de presse. Voilà comment la directive propose de forcer la main aux plateformes. Etant responsables de tout ce qui circule sur leurs sites, les plateformes auront intérêt à négocier une rente, à l’avance, avec les éditeurs de presse pour éviter toute poursuite.
Un tel arrangement n’est pas une victoire pour les éditeurs mais la promesse d’être définitivement lié aux plateformes et aux sites de partage de contenu. En effet, leur rémunération dépendant du nombre de partages sur les plateformes, les éditeurs auront tout intérêt à publier directement dessus et à multiplier les titres accrocheurs pour attirer les clics ! Bref, les éditeurs seront devenus les pigistes des plateformes.
Mais l’erreur réglementaire va plus loin. A présent, non contents de consacrer la dépendance des éditeurs de presse aux plateformes, il semblerait que nos eurodéputés, sous les conseils mal avisés du lobby de la presse, soient favorables à l’extension de ce droit voisin aux agences de presse. Normal me direz-vous ! Editeurs de presse, agences de presse, quelle différence ! Eh bien, la différence est de taille. Dans le cas français, les éditeurs de presse signent des accords commerciaux avec l’Agence France Presse, qui leur permettent d’utiliser les informations qu’elle diffuse. Dès lors, lorsque l’utilisateur d’une plateforme diffuse une information AFP reprise sur le site d’un éditeur de presse, c’est l’AFP qui doit être rémunérée par la plateforme et non l’éditeur de presse. De même, si un moteur de recherche indexe des dépêches AFP reproduites par les éditeurs de presse, ces derniers ne seront pas payés puisqu’en dernier ressort, c’est l’AFP qui a produit le contenu. Ce que les éditeurs de presse devaient gagner d’un côté, ils le perdront de l’autre, et cela, même s’ils paient déjà un abonnement à l’AFP. Or, devant une telle injustice, il y a fort à parier que les éditeurs de presse devront négocier avec l’AFP, comme les plateformes le feront avec les éditeurs de presse.
Mais pourquoi la logique s’arrêterait-elle là ? Pour chaque information partagé par un utilisateur sur une plateforme, il faudra alors retracer l’itinéraire du contenu en question jusqu’à son origine. Inévitablement se pose alors la question de la rémunération des différents intermédiaires. Si l’utilisateur d’une plateforme y partage un article d’un quotidien citant une information exclusive dévoilée par un second quotidien et celle-ci faisant écho à des révélations de l’AFP, qui devra être payé par la plateforme ? Faudra-t-il définir un arrangement pour chaque cas particulier ? Quelle que soit la réponse, il faudra des algorithmes capables de retracer l’origine de l’information, de distinguer entre une information AFP « brute » et une information « raffinée » par un éditeur de presse. Autant dire que tous les médias partageant des informations AFP vont voir leurs coûts d’investissement informatique augmenter dramatiquement au risque de se trouver hors la loi. Voilà comment, en élargissant le droit voisin à l’AFP, la directive va créer une véritable usine à gaz dont les éditeurs de presse sortiront forcément perdants.
Mark Risher, responsable chez Google, a récemment pris la parole pour mettre en garde contre les trois fléaux principaux qui polluent les messageries et mettent en danger les utilisateurs.
Pour Mark Risher, il y a actuellement 3 tendances qui mettent principalement en danger les utilisateurs sur Internet, tous sont directement véhiculés par les messageries.
La principale menace selon l'expert de Google réside encore et toujours dans le phishing (hameçonnage), une pratique qui continue de faire des millions de victimes chaque année dans le monde. Le système est assez simple à la base : vous recevez un courriel d'un organisme de confiance (en apparence) de type banque, prestataire d'énergie, assurance, prestation sociale... Qui vous demande de mettre à jour votre dossier avec un lien. Le lien renvoie vers une copie du site associé et demande ensuite à l'utilisateur de s'identifier... Les données sont alors collectées et récupérées par des pirates qui les exploitent en fonction de leur nature...
La situation est d'autant plus préoccupante que les internautes continuent d'adopter des pratiques à risques. En effet, ces combinaisons d'identifiants et mots de passe se retrouvent à la vente sur le darkWeb, et Mark Risher déplore ainsi qu' "On constate que 17% de ces combinaisons sont réutilisées par les internautes. C’est souvent la cause de multiples piratages et vol de données, qui multiplient ainsi les risques par 10 de nouveaux piratages, tandis que le vol d’identifiants, c’est x 40".
Et le phishing adopte de nouvelles formes de plus en plus complexes pour se rendre plus crédible et efficace avec l'apparition du Spearphishing et du Whaling.
Désormais, les pirates exploitent l'ensemble des données qu'ils peuvent collecter sur leur cible pour personnaliser les attaques. L'accès aux réseaux sociaux via des bases de données piratées consultables en accès libre permet de monter des dossiers élaborés pour mieux cibler les victimes en les appâtant avec des informations personnelles laissant bien supposer que l'interlocuteur est effectivement fiable. Les emails arborent ainsi parfois directement des vrais numéros de dossier, les derniers chiffres de votre carte bancaire, le nom de votre employeur...
Les individus ne sont également plus les seules cibles des pirates. En visant des employés, les pirates peuvent également plus facilement atteindre des sociétés entières, créant des brèches pour s'infiltrer dans les réseaux d'entreprise.
Le Whaling est une pratique encore plus redoutable : un pirate se sert d'éléments récupérés sur la toile pour se faire passer pour un supérieur ou un collègue et prétexte une situation urgente pour demander la communication de mots de passe ou de données sensibles.
Comme dans bien des cas, ces pratiques misent globalement sur un maillon faible : l'humain qui reste le principal fautif dans les cas de piratage par courriel.
Outre l'adoption de comportements plus sécuritaires, il est possible de limiter les risques en optant pour une protection efficace comme le service anti-spam Altospam (une société française d'ailleurs, qui propose ce service très efficace depuis plus de 15 ans) mais vous pourrez également utiliser l'antispam (s'il existe) intégré à votre suite de sécurité ou dans un antivirus évolué, même s'ils sont généralement moins efficaces qu'un outil dédié (comme c'est le cas pour les outils antimalwares également). En effet, certains éditeurs comme Google ou Altospam ont développé des solutions permettant de mieux traiter automatiquement les tentatives de phishing et autres attaques. En n'affichant plus ces messages toxiques à l'utilisateur, le risque de faire l'objet d'un piratage ou d'un vol de données est ainsi réduit.
Malgré tout, on ne saurait trop conseiller deux éléments principaux pour limiter les risques : ne jamais cliquer dans un lien intégré à un email, multiplier les logins et mots de passe (un différent à chaque fois est la meilleure solution) tout en les changeant régulièrement.
Les tests d'ADN pour connaître ses « origines » explosent aux États-Unis. Mais les entreprises privées qui les réalisent revendent souvent ces données, pourtant si précieuses.
Ils veulent savoir d’où viennent leurs épais sourcils, leurs tâches de rousseur ou leur teint olive. Un peu d’Irlande, de bassin méditerranéen ou d’Amérique centrale. Aux États-Unis, de plus en plus d’Américains choisissent de passer un test ADN afin de connaître leurs origines. Pour cela, nul besoin de se rendre dans des laboratoires spécialisés. Pour quelques dizaines de dollars, ils peuvent commander un kit de prélèvement sur internet ou même aller le chercher directement dans la pharmacie de leur quartier.
Pour savoir d’où ils « viennent », ils déposent un peu de salive dans un tube en plastique puis l’envoient par la poste pour le faire analyser. Plus de 10 millions d’Américains et Américaines y ont déjà eu recours, selon une étude publiée dans le magazine scientifique Genome biology. « Si on se projette d’ici à 2021, ce sont plus de 100 millions de profils ADN qui auront été analysés. La croissance réelle excèdera probablement nos prédictions en raison de l’augmentation croissante de la publicité et du prix de séquençage de l’ADN qui baisse », expliquent les deux auteurs de l’étude. Mais est-ce vraiment une bonne idée ?
De précieuses données de santé
Le séquençage du génome a fait des progrès fulgurants. Il a fallu 13 ans, de 1990 à 2003, pour séquencer un génome entier pour la première fois. 15 ans plus tard, en 2018, cela ne prend plus que quelques jours. Et les tests grand public, eux, n’en analysent en fait qu’une partie.
Cette technologie n’est pas chère, facile d’accès, et produit des résultats rapides. Pourquoi ne pas y céder et découvrir les secrets cachés dans nos doubles hélices d’ADN ? Peut-être parce que nos informations génétiques font partie de ce que nous avons de plus cher. Et pour cause, les grands groupes se l’arrachent… Cet été, 23andMe, l’une des principales entreprises de ce secteur, a revendu la quasi-totalité des données qu’elle possédait au géant de l’industrie pharmaceutique GlaxoSmithKline. 80 % des utilisateurs de ce kit ont autorisé le partage de leurs données, faute d’avoir bien lu les petites lignes des conditions du contrat.
23andMe assure n’utiliser les données que des clients qui ont donné leur autorisation, et qui plus est, en les anonymisant. « Personne ne peut être identifié », peut-on lire dans un communiqué publié par l’entreprise. Mais plusieurs voix dissidentes commencent à se faire entendre au sein de la communauté scientifique, comme sur le site du Times. « Ces informations ne sont jamais sécurisées à 100 %. Le risque est amplifié quand une organisation les partage avec une autre. Quand les informations vont d’un endroit à l’autre, il y a toujours un risque qu’elles soient interceptées par d’autres acteurs », estime Peter Pitts, le président du Center for medicine in the public interest (CMPI), une association de recherche à but non lucrative.
Un futur sans vie privée ?
Ces données destinées à découvrir ses origines seront finalement utilisées par un laboratoire pharmaceutique pour mettre sur le marché de nouveaux médicaments, notamment dans la maladie de Parkinson. « Ensemble, GSK et 23andme vont s’employer à traduire ces informations génétiques et phénotypiques dans nos activités de R&D pour développer la médecine de précision, mettre en point des sous-groupes de patients et constituer plus facilement des cohortes pour les études cliniques », explique l’entreprise pharmaceutique dans un communiqué.
Il suffit que 2 % de la population donne son ADN pour que tous les Américains puissent être identifiés
Surtout, la notion de vie privée risque d’être considérablement restreinte dans les années à venir. Il suffit que 2 % de la population donne son ADN pour que tous les Américains puissent être identifiés, selon une étude publiée dans la revue Science par Yaniv Erlich, le responsable scientifique de MyHeritage, une entreprise de tests ADN basée en Israël. Aujourd’hui déjà, plus de 60 % des Américains d’origine européenne peuvent être identifiés grâce aux bases de données de généalogie génétique publiques, comme GEDmatch.
Cette base de données a même permis à la police californienne de retrouver l’identité d’un tueur, en téléchargeant simplement son ADN sur le site. Sur GEDmatch, où tous les ADN sont enregistrés au format texte, avec un nom et une adresse mail associée, il est possible de retrouver les ADN proches des nôtres. La police a réussi à mettre la main sur un cousin au 3e degré du tueur, alors que le meurtre datait de 1980. La technique est maintenant utilisée à l’échelle nationale pour résoudre les cold cases, avec déjà 13 personnes arrêtées en 5 mois.
Si dans ce cas-là, la génétique a été utilisée à bon escient, le contraire peut vite arriver. C’est Yaniv Erlich lui-même qui met en garde contre cette technique dans l’étude publiée sur le site de Science : « Même si les décideurs et le grand public peuvent être en faveur de l’amélioration des outils médico-légaux pour résoudre les crimes, ils reposent sur des bases de données ouvertes à tout le monde. Par conséquent, la même technique pourrait être utilisée de façon abusive dans des buts néfastes, comme l’identification inversée d’individus ayant participé à des recherches à partir de leurs données génétiques. »
Les prédictions médicales sont peu fiables
Voilà donc bien des écueils auxquels se soumettent personnes souhaitant simplement savoir qui ont été leurs ancêtres. D’autant que le test ADN ne permet pas vraiment d’avoir un temps d’avance sur les risques qui planent sur notre santé. La Food and Drug Administration (FDA), le gendarme du médicament américain, avait imposé un moratoire sur les tests de santé de 23andMe en 2013.
Il a finalement été levé en 2017 pour une dizaine de maladies, comme Alzheimer, Parkison, le risque de thromboses ou de maladies coeliaques. Là encore, le ton restait prudent. « Il est important que les gens comprennent que le risque génétique n’est qu’une pièce d’un puzzle plus large. Cela ne veut pas dire qu’ils vont, ou ne vont pas développer une maladie », déclarait alors Jeffrey Shuren, directeur du centre de la FDA en charge des dispositifs médicaux. Le résultat génétique reste une indication et ne permet aucune projection avérée.
En attendant, des vidéos méticuleusement mises en scène se multiplient sur Youtube, montrant des anonymes en train de découvrir leurs résultats. Beaucoup d’entre elles ont été postées par Momondo, un site de… comparateurs de voyages. À l’occasion d’un concours, l’enseigne offrait même un voyage dans le pays « de ses racines » à un grand gagnant. Ce genre de pratiques risque de s’étendre à l’Europe. AncestryDNA et 23andMe n’envoient pas leurs kits en France, mais des produits similaires sont disponibles sur Amazon. Myheritage a ouvert sa livraison à la France, bien que les tests génétiques de convenance n’y soient pas autorisés. Ils ont même récemment fait une promo pour Halloween. Reste à savoir si le jeu en vaut la chandelle.
Attendu depuis près de 15 ans, le dossier médical partagé (DMP), sorte de carnet de santé numérique, pourrait bientôt devenir une réalité pour tous les Français, la ministre de la Santé Agnès Buzyn devant annoncer mardi sa généralisation.
Lundi, elle a invité "tous les Français" à "se faire ouvrir" un DMP, soit sur internet, soit chez leur pharmacien, vantant un outil permettant des "gains de temps, peut-être des économies" en rationalisant les soins, mais "avant tout un outil de partage d'information pour faire de la meilleure médecine".
Le directeur général de l'Assurance maladie, Nicolas Revel, et le président de France Assos Santé, qui regroupe 80 associations de patients, participeront au "lancement officiel" de la nouvelle version de cet outil présenté dès 2004 par Philippe Douste Blazy, l'un des prédécesseurs de Mme Buzyn.
Mais les curieux peuvent d'ores et déjà se rendre sur le site dmp.fr, qui permet à tous les volontaires de créer leur carnet en ligne, et télécharger l'application mobile dédiée.
"Gratuit, confidentiel et sécurisé", le DMP "conserve précieusement" les informations de santé du patient, libre de les partager avec son médecin traitant et "tous les professionnels de santé" de son parcours, explique l'Assurance maladie, chargée de la nouvelle mouture, testée depuis 2016 dans neuf départements.
D'après elle, "le DMP est le seul service" qui permette de "retrouver dans un même endroit" son historique de soins des 24 derniers mois, ses antécédents médicaux (pathologie, allergies...), ses résultats d'examens (radio, analyses biologiques...), les comptes-rendus d'hospitalisation ou encore les coordonnées des proches à prévenir en cas d'urgence.
De quoi satisfaire Fabienne, 57 ans, dont l'allergie aux sulfamides (antibiotique) a failli lui coûter la vie il y a quelques années, après une opération. "Je savais que j'étais allergique à un médicament mais ne me souvenais plus lequel, alors l'anesthésiste a supposé qu'il s'agissait de la pénicilline".
Eviter ce type d'incident, mais aussi les interactions médicamenteuses dangereuses ou les actes redondants et inutiles est la vocation du DMP, également censé favoriser la coopération entre les professionnels de santé. Il est de ce fait particulièrement recommandé aux personnes atteintes de pathologies chroniques ou aux femmes enceintes.
"pas obligatoire"
Le DMP est tombé dans le giron de l'Assurance maladie en 2016, en vertu de la loi santé de Marisol Touraine, soucieuse de refonder un dispositif au point mort malgré son coût, d'"au moins 210 millions d'euros" entre 2004 et fin 2011, selon la Cour des comptes...
Bien loin des milliards d'euros d'économies visés par M. Douste-Blazy.
La première phase de développement a déjà permis de créer 550.000 DMP en 18 mois, jusqu'à mai 2018. En y ajoutant ceux de la décennie précédente, "plus de 1,2 million de DMP" étaient ouverts au début de l'été, selon l'Assurance maladie
C'est encore loin de l'"objectif de 40 millions de DMP ouverts d'ici à 5 ans" inscrit dans un accord entre l'Assurance maladie et l'Union nationale des professionnels de santé (UNPS).
Mais plusieurs innovations devraient ôter certains freins, notamment chez les professionnels de santé, qui ont boudé la précédente version, pas assez ergonomique, trop chronophage.
Les patients pourront cette fois ouvrir eux-même leur dossier en ligne ou auprès des agents des caisses d'assurance maladie, en plus des établissements de santé et des professionnels, pour lesquels l'Assurance maladie pourrait négocier "des mécanismes d'incitation" financière, comme elle l'a déjà fait avec les pharmaciens, qui toucheront un euro par DMP ouvert.
En outre, c'est l'Assurance maladie qui injectera automatiquement dans le DMP "l'historique des remboursements" des actes et des médicaments sur les deux dernières années, alors que les précédents DMP étaient plutôt vides.
Côté patient, le DMP "n'est pas obligatoire et n'a aucun impact sur (les) remboursements", peut-on lire sur le site dmp.fr.
"Seul" le médecin traitant "peut accéder à l'ensemble des informations", le patient pouvant bloquer les professionnels de son choix, ajouter ou masquer certains documents, ou tout bonnement supprimer son DMP, dont "les données seront conservées pendant 10 ans".
Reste à voir si les hôpitaux et les cabinets médicaux disposeront de logiciels capables d'intégrer facilement des documents au DMP, et comment la protection du secret médical sera garantie.
La connexion à un compte Google rend obligatoire l'activation de JavaScript pour un navigateur.
Avis à ceux ayant par exemple recours à des extensions pour bloquer JavaScript. Désormais, la connexion à un compte Google ne pourra pas se faire si JavaScript est désactivé pour un navigateur. Cette mesure est justifiée par un impératif de sécurité.
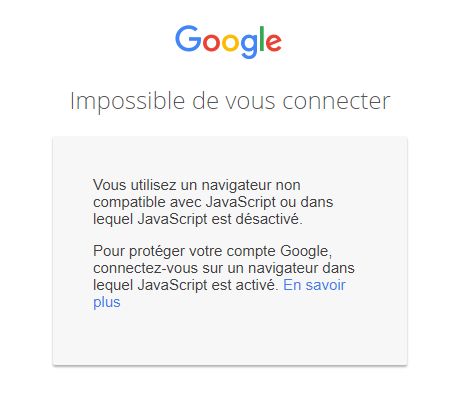
Quand les identifiants sont saisis sur la page de connexion au compte, Google explique procéder à une évaluation des risques et n'autorise la connexion que si rien ne semble suspect. Une telle analyse exige l'activation de JavaScript.
Dans l'absolu, Google avance que seulement 0,1 % de ses utilisateurs choisissent de bloquer JavaScript. Un langage de programmation dont il est difficile de se passer pour l'interactivité avec les sites web.
Google a par ailleurs introduit cette semaine une version 3 de sa technologie reCAPTCHA qui a recours à une évaluation des risques en s'appuyant justement sur JavaScript.
Pour faire la différence entre un utilisateur humain et un bot, plus aucune action n'est requise du côté de l'utilisateur. La recette - forcément - secrète se base sur l'interaction des utilisateurs avec un site et ses sections.
En libre téléchargement au format PDF, un cahier de vacances pour les 7-11 ans sur la sécurité numérique.
NDLR : Il parait qu'officiellement en France il ne faut plus dire "fake news", mais infox. Si si si, c''était au Journal officiel, donc, ce n'est pas une fake news ... heu je veux dire une infox.
La CNIL a mis en demeure l'école 42, fondée par Xavier Niel, pour son système de vidéosurveillance, jugé excessif. L'établissement à deux mois pour se mettre en conformité, sous peine de sanctions.
La Commission nationale informatique et libertés (CNIL) a annoncé mardi avoir mis en demeure le 8 octobre l'école informatique 42, créée par le fondateur de Free Xavier Niel, pour « vidéosurveillance excessive » au sein de l'établissement.
L'association 42, qui a créé l'école éponyme en 2013, est mise en demeure de « mettre en conformité avec la loi Informatique et Libertés son système de vidéosurveillance » dans un délai de deux mois sous peine de sanction, a précisé l'autorité française de protection des données personnelles dans un communiqué.
Deux mois pour se mettre en conformité
Au cours d'un contrôle effectué en février 2018, la CNIL a constaté « que des caméras filmaient en permanence les espaces de travail des étudiants, les bureaux dédiés au personnel administratif ainsi que des lieux de vie », sans que les personnes filmées n'en soient « correctement informées ».
Dans son communiqué, la CNIL rappelle que les images issues du dispositif doivent être réservées aux personnes habilitées, or le contrôle a révélé que les étudiants avaient accès aux images sur leur espace personnel au sein du réseau intranet de l'école.
L'an dernier, des étudiantes de l'école avaient dénoncé les comportements déplacés qu'elles subissaient.
Il y a des révolutions qui se font en silence. L’intégration d’Internet dans les foyers des milieux populaires en est un bon exemple.
Où situer la « fracture numérique » ?
On a, au début des années 2000, beaucoup parlé de « fracture numérique » en s’intéressant à la fois aux inégalités d’accès et d’usages. Les rapports annuels du CREDOC montrent que les catégories populaires ont commencé à rattraper leur retard de connexion depuis une dizaine d’années : entre 2006 et 2017, en France, la proportion d’employés ayant une connexion Internet à domicile est passée de 51 % à 93 %, celle des ouvriers de 38 à 83 % (CREDOC 2017 : 48).
C’est désormais l’âge et non le revenu ou le niveau de diplôme qui est le facteur le plus clivant (parmi ceux qui ne se connectent jamais à Internet, huit personnes sur dix ont 60 ans ou plus). Si la question de l’accès est en passe d’être résolue, les usages des classes populaires restent moins variés et moins fréquents que ceux des classes moyennes et supérieures, nous apprennent ces mêmes rapports. Les individus non diplômés ont plus de mal à s’adapter à la dématérialisation des services administratifs, font moins de recherches, pratiquent moins les achats, se lancent très rarement dans la production de contenus. Bref, il y aurait en quelque sorte un « Internet du pauvre », moins créatif, moins audacieux, moins utile en quelque sorte…
Changer de focale
Peut-être faut-il adopter un autre regard ? Ces enquêtes statistiques reposent sur un comptage déploratif des manques par rapport aux pratiques les plus innovantes, celles des individus jeunes, diplômés, urbains. On peut partir d’un point de vue différent en posant a priori que les pratiques d’Internet privilégiées par les classes populaires font sens par rapport à leur besoins quotidiens et qu’elles sont des indicateurs pertinents de leur rapport au monde et des transformations possibles de ce rapport au monde.
Comme Jacques Rancière l’a analysé à propos des productions écrites d’ouvriers au XIXe siècle, il s’agit de poser l’égalité des intelligences comme point de départ de la réflexion pour comprendre comment « une langue commune appropriée par les autres » peut être réappropriée par ceux à qui elle n’était pas destinée. (Rancière 2009 : 152).
Un tel changement de focale permet d’entrevoir des usages qui n’ont rien de spectaculaire si ce n’est qu’ils ont profondément transformé le rapport au savoir et aux connaissances de ceux qui ne sont pas allés longtemps à l’école. Ce sont par exemple des recherches sur le sens des mots employés par les médecins ou celui des intitulés des devoirs scolaires des enfants. Pour des internautes avertis, elles pourraient paraître peu sophistiquées, mais, en attendant, elles opèrent une transformation majeure en réduisant l’asymétrie du rapport aux experts et en atténuant ces phénomènes de « déférence subie » des classes populaires face au monde des sachants – qu’Annette Lareau a analysée dans un beau livre, Unequal Childhoods (2011).
Recherche en ligne : s’informer et acheter
Des salariés qui exercent des emplois subalternes et n’ont aucun usage du numérique dans leur vie professionnelle passent aussi beaucoup de temps en ligne pour s’informer sur leur métier ou leurs droits : le succès des sites d’employés des services à la personne est là pour en témoigner. Des assistantes maternelles y parlent de leur conception de l’éducation des enfants, des aides-soignantes ou des agents de service hospitaliers de leur rapport aux patients. On pourrait aussi souligner tout ce que les tutoriels renouvellent au sein de savoir-faire traditionnellement investis par les classes populaires : ce sont des ingrédients jamais utilisés pour la cuisine, des manières de jardiner ou bricoler nouvelles, des modèles de tricot inconnus qui sont arrivés dans les foyers.
Apprendre donc, mais aussi acheter. Pour ceux qui vivent dans des zones rurales ou semi rurales, l’accès en quelques clics à des biens jusqu’alors introuvables dans leur environnement immédiat paraît a priori comme une immense opportunité. Mais en fait, les choses sont plus compliquées. La grande vitrine marchande en ligne est moins appréciée pour le choix qu’elle offre que pour les économies qu’elle permet de réaliser en surfant sur les promotions. C’est la recherche de la bonne affaire qui motive en priorité : c’est aussi qu’elle permet de pratiquer une gestion par les stocks en achetant par lots. En même temps, ces gains sont coupables puisqu’ils contribuent à fragiliser le commerce local, ou du moins ce qu’il en reste.
Dans une société d’interconnaissance forte où les commerçants sont aussi des voisins, et parfois des amis, la trahison laisse un goût amer des deux côtés. À l’inverse, les marchés de biens d’occasion entre particuliers, à commencer par Le Bon Coin qui recrute une importante clientèle rurale et populaire, sont décrits comme des marchés vertueux : ils offrent le plaisir d’une flânerie géolocalisée – c’est devenu une nouvelle source de commérage !-, évitent de jeter, et permettent de gagner quelques euros en sauvegardant la fierté de l’acheteur qui peut se meubler et se vêtir à moindre coût sans passer par des systèmes de dons. L’achat en ligne a donc opéré une transformation paradoxale du rapport au local, en détruisant certains liens et en en créant d’autres.
Lire et communiquer sur Internet
Enfin, Internet c’est une relation à l’écrit, marque de ceux qui en ont été les créateurs. Elle ne va pas de soi pour des individus qui ont un faible niveau de diplôme et très peu de pratiques scripturales sur leur lieu de travail. Le mail, qui demande une écriture normée, est largement délaissé dans ces familles populaires : il ne sert qu’aux échanges avec les sites d’achat et les administrations -le terme de démêlés serait en l’occurrence plus exact dans ce dernier cas.
C’est aussi qu’il s’inscrit dans une logique de communication interpersonnelle et asynchrone qui contrevient aux normes de relations en face à face et des échanges collectifs qui prévalent dans les milieux populaires. Facebook a bien mieux tiré son épingle du jeu : il permet l’échange de contenus sous forme de liens partagés, s’inscrit dans une dynamique d’échange de groupe et ne demande aucune écriture soignée. Ce réseau social apparaît être un moyen privilégié pour garder le contact avec les membres de sa famille large et les très proches, à la recherche d’un consensus sur les valeurs partagées. C’est un réseau de l’entre-soi, sans ouverture particulière sur d’autres mondes sociaux.
Car si l’Internet a finalement tenu de nombreuses promesses du côté du rapport au savoir, il n’a visiblement pas réussi à estomper les frontières entre les univers sociaux.
Dominique Pasquier, sociologue, directrice de recherche CNRS est l’auteur de « L’Internet des familles modestes. Enquête dans la France rurale ». Paris, Presses des Mines, 2018.
Google envisagerait de faire payer Android aux constructeurs de smartphones en Europe.
(CCM) — A compter du 1er février 2019, Google devrait demander aux fabricants de smartphones et tablettes de payer pour installer Android sur leurs appareils. C'est la réponse du géant américain aux injonctions de la Commission Européenne qui lui reproche d'abuser de sa position dominante sur le marché de l'Internet mobile.
Les documents internes que The Verge (lien en anglais) s'est procurés détaillent les tarifs applicables dès février prochain. La licence d'Android pourrait coûter jusqu'à 40 $ par smartphone, pour un modèle haut de gamme vendu en Europe. Pour les modèles d'entrée de gamme, la licence ne serait que de 2,5 $. Entre ces deux extrêmes, Google fait varier la facture selon la qualité de l'écran du smartphone ou de la tablette tactile (exprimée en ppp, ou taux de pixel par pouce).
Bien entendu, cette tarification ne concernera que les ventes de nouveaux appareils. Il n'est pas question à ce stade de faire payer les utilisateurs actuels d'Android. Mais pour Google, ce changement de politique tarifaire marque un véritable tournant. Jusqu'à présent, le géant américain avait misé sur la gratuité de son OS mobile pour en faire une référence sur le marché. Son modèle reposait alors sur l'utilisation liée d'Android, de Google Search, de Google Chrome et de ses autres applis mobiles, très rémunératrices.
C'est cette combinaison que la Commission Européenne a dénoncé. Désormais, Google a l'obligation de séparer l'utilisation de son système d'exploitation Android et celle de ces autres applications (recherche, navigateur, cartographie...). Reste à voir comment les marques de téléphone répercuteront le coût de cette licence Android dans les prix de vente de leurs appareils.
Après une rumeur de courte durée, Microsoft a annoncé début juin l'acquisition de la plateforme web d'hébergement et de gestion de développement de logiciels GitHub, pour le montant de 7,5 milliards de dollars en actions. Mais comme il est coutume pour ce genre de transaction, la firme de Redmond devait se soumettre à un examen règlementaire de différentes autorités de régulation dans le monde afin de finaliser le rachat de GitHub.
La décision du régulateur européen de la concurrence devait être connue ce vendredi 19 octobre, et comme on s'y attendait, la Commission européenne a donné son feu vert pour la finalisation de cette opération, sans condition. Dans un communiqué, la Commission dit être arrivée à la conclusion que « l'opération n'entraverait pas l'exercice d'une concurrence effective sur les marchés en cause et que Microsoft n'aurait aucune raison de s'en prendre à la nature ouverte de la plateforme GitHub. »
L'annonce de l'opération de rachat de GitHub par Microsoft avait en effet immédiatement suscité des inquiétudes ; lesquelles inquiétudes semblent toutefois avoir disparu après quelques communications. Dans un communiqué juste après l'annonce, Microsoft a mis en avant quelques avantages qui pourraient découler de cette opération, pour la société elle-même, pour GitHub et pour les développeurs : « Ensemble, les deux sociétés permettront aux développeurs de faire plus à chaque étape du cycle de vie du développement », expliquait le géant du logiciel. Cet accord permettrait aussi « d'accélérer l'utilisation de GitHub en entreprise et d'apporter les outils et services de développement de Microsoft à de nouveaux publics. »
GitHub va en outre continuer à fonctionner de manière indépendante pour fournir une plateforme ouverte à tous les développeurs de tous les secteurs. « Les développeurs continueront à utiliser les langages de programmation, les outils et les systèmes d'exploitation de leur choix pour leurs projets, et pourront toujours déployer leur code sur n'importe quel système d'exploitation, n'importe quel cloud et n'importe quel appareil », a assuré Microsoft dans son communiqué. Nat Friedman, vétéran de l'open source et nouveau CEO de GitHub s'est également montré rassurant après un communiqué et une séance de questions et réponses sur l'opération.
Bref, Microsoft a mené une bonne communication pour rassurer la communauté et les régulateurs. Pour sa part, la Commission européenne dit en effet avoir constaté que « le regroupement des activités de Microsoft et de GitHub sur les marchés concernés [plateformes de collaboration sur du code source ; et éditeurs de code et environnements de développement, NDLR] ne poserait aucun problème de concurrence parce que l'entité issue de la concentration resterait confrontée à une concurrence importante de la part d'autres acteurs sur ces deux marchés. »
La Commission dit avoir également cherché à savoir s'il existait un risque d'affaiblissement de la concurrence si Microsoft devait tirer parti de la popularité de GitHub pour stimuler les ventes de ses propres outils DevOps et services cloud. « Plus particulièrement, la Commission a cherché à savoir si Microsoft serait en mesure de poursuivre le rapprochement de ses propres outils DevOps et services cloud avec GitHub et aurait un intérêt à le faire, tout en restreignant une intégration de ce type avec les outils DevOps et les services cloud tiers », peut-on lire dans le communiqué. Mais « il est ressorti de l'enquête sur le marché que Microsoft ne disposerait pas d'un pouvoir de marché suffisant pour porter préjudice à la nature ouverte de GitHub, au détriment d'outils DevOps et de services cloud concurrents. La raison en est qu'un tel comportement réduirait la valeur de GitHub aux yeux des développeurs désireux et en mesure de changer de plateforme », explique la Commission.
Sur cette base, la Commission est donc parvenue à la conclusion selon laquelle l'opération ne poserait des problèmes de concurrence sur aucun des marchés concernés et l'a autorisée sans condition. Microsoft obtient ainsi le feu vert du régulateur européen pour la finalisation du rachat de GitHub.
Il existait déjà depuis 2017 mais faisait face à de nombreuses critiques: le TES, un méga fichier centralisant les données de 60 millions de Français, vient d'être finalement validé par le Conseil d'Etat.
Le nom de TES ne vous dit rien? Pourtant, ce fichier créé par le gouvernement français en sait long sur vous.
Car derrière cette appellation (TES signifie Titres Électroniques Sécurisés) se cache une énorme base de données, mise en place en 2017 afin de centraliser les informations personnelles et biométriques de la quasi-totalité des Français.
Face aux risques qu'un tel dispositif peut présenter pour la sécurité, le Conseil d'Etat avait été saisi par la Quadrature du Net, la Ligue des Droits de l’Homme et le think tank Génération Libre.
Ce vendredi 19 octobre, la plus haute instance juridique française a rendu sa décision: la collecte de données personnelles et sensibles par le fichier TES ne porte "pas au droit des individus au respect de leur vie privée une atteinte disproportionnée aux buts de protection de l’ordre public en vue desquels ce traitement a été créé".
On vous en dit plus.
Qu'est-ce-que c'est?
La base de données TES centralise dans un seul et même fichier les informations biométriques et personnelles des Français.
Ce dispositif remplace ainsi les deux fichiers précédents existants, l'un relatif aux données des détenteurs d'un passeport, l'autre à celles des possesseurs d'une carte nationale d'identité.
pourquoi le mettre en place?
Lors de son déploiement il y a plus d'un an, le gouvernement français avait justifié sa création par la lutte contre la fraude documentaire (l’usurpation ou la falsification par exemple).
Le fichier est également destiné à faciliter la délivrance ou le renouvellement des titres de séjour.
Quelles informations sont collectées?
Le fichier TES centralise toutes les données affichées sur votre carte nationale d'identité ou votre passeport: le nom de famille, le nom d’usage, les prénoms, la date et le lieu de naissance, le sexe, la couleur des yeux, la taille, les photos du visage, des empreintes digitales (sauf si vous avez opposé votre refus) et de la signature du demandeur, et éventuellement d'autres informations comme l'adresse postale.
Les noms et prénoms des parents, leur lieu et date de naissance, leur nationalité peuvent également être récoltés par le fichier TES.
combien de temps sont conservées ces données?
S'il s'agit d'un passeport, les informations seront conservées 15 ans.
Pour une carte nationale d'identité, la durée de conservation passe à 20 ans.
Elle est respectivement de 10 et 15 ans pour le passeport et la carte d'identité d'un mineur.
Quel est le risque?
Avec un stockage d'une telle ampleur, le fichier TES inquiète et fait redouter des dérives.
La principale crainte porte notamment sur le détournement de données sensibles, comme les empreintes ou le visage, qui pourraient faciliter l'identification des personnes sur les caméras de surveillance.
Sans compter le risque de piratage et toutes les questions d'ordre éthique que peut poser un tel dispositif...
Le décret du fichier des Titres éléctroniques sécurisés (TES), ayant fait l'objet de nombreuses requêtes en annulation auprès du Conseil d'Etat depuis sa parution fin 2016, a été validé par ce dernier le 18 octobre. Regroupant les informations de plus de 66 millions de Français et à l'époque pointé du doigt par la CNIL, le secrétariat d'Etat au Numérique ou encore l'ANSSI, ce fichier ne constitue pas une « atteinte disproportionnée » à la vie privée selon le Palais Royal.
Le Conseil d’État n’a eu cure de toutes les requêtes adressées contre le décret « autorisant la création d'un traitement de données à caractère personnel relatif aux passeports et aux cartes nationales d'identité ». L’institution a rejeté ces demandes d’annulation de la base de données des Titres électroniques sécurisés (TES) juge, dans un arrêt, que sa création ne constitue pas une « atteinte disproportionnée » à la vie privée.
Lancée officiellement début novembre 2016 suite à ce fameux décret pris le 28 octobre précédent, la base visant à centraliser les données personnelles des 66,6 millions de Français (identité, couleur des yeux, domicile, photographie ou encore empreintes digitales) en a fait bondir plus d’un. Mis en œuvre sous le mandat de François Hollande, TES devait apporter des « simplifications administratives » selon le ministre de l'Intérieur de l’époque, Bernard Cazeneuve.
Un décret passé en douce
A l’époque, même la Secrétaire au Numérique, Axelle Lemaire, était montée au créneau, ainsi que le Conseil national du Numérique qui, en dehors de critiquer le fait que le décret ait été pris en plein week-end de la Toussaint, alertait sur de potentiels problèmes de sécurité. L’Anssi et la Dinsic avaient également fait part de leur inquiétude à ce sujet en janvier 2017 dans un rapport adressé à Bruno Leroux, remplaçant de M. Cazeneuve à l’Intérieur.
Ces vives réactions n’avaient pas empêché le lancement de la base de données, en test dans un premier temps en Bretagne et dans les Yvelines, puis dans tout l’Hexagone fin mars 2017. Bien que les Français ne peuvent en principe pas s’opposer à la conservation de leurs données dans cette base, un décret paru en mai 2017 les autorise néanmoins à pouvoir refuser la numérisation et l'enregistrement de leurs empreintes digitales dans TES lors de la création d’une carte d’identité... Au moins une information qui ne sera pas à la merci des pirates.
Fin du support natif des flux RSS / Atom et des live bookmarks dans Firefox en version 64. Il faudra passer par des extensions.
C'était dans les tuyaux et cela a été officialisé. C'est finalement avec la version 64 de Firefox en fin d'année que le lecteur de flux intégré et le support natif des marque-pages dynamiques (live bookmarks) seront supprimés.
Il s'agit donc de la fonctionnalité permettant à Firefox de détecter quand un utilisateur accède à un flux RSS / Atom et l'affiche sur une page pour permettre un abonnement et une lecture. Les entrées du flux se retrouvent dans les marque-pages dynamiques.
Mozilla n'enterre pas RSS, mais considère que le meilleur moyen pour répondre aux besoins en la matière est du côté des WebExtensions. Qui plus est, les possibilités natives (prévisualisation des flux et live bookmarks) ne seraient utilisées que dans environ 0,01 % des sessions.
La décision de retrait a également été motivée par le fait que les marque-pages dynamiques s'appuient sur un vieux moyen d'accès à la base de données des marque-pages qui n'est plus en adéquation avec le niveau de performance attendu depuis le moteur de rendu Quantum.
De même, le lecteur de flux intégré dispose d'un parser XML spécifique et distinct de celui principal de Firefox. Des efforts de maintenance et mise à niveau sont considérés superflus au regard de la faible utilisation, et surtout avec les alternatives proposées par les WebExtensions.
Françoise Nyssen a quitté le ministère de la Culture. Pour la remplacer, le gouvernement a fait le choix du député Franck Riester. Le parlementaire a notamment été l'ancien rapporteur de la loi Hadopi et a siégé au collège de la Haute Autorité pendant six ans.
Approuvée par le Parlement européen mi-septembre, la directive sur le droit d'auteur doit maintenant faire l'objet d'un accord avec le Conseil et la Commission. Officiellement, l'objectif est de trouver un terrain d'entente avant la fin de l'année.
Un accord sur la directive européenne sur le droit d’auteur, qui a suscité de forts débats ces derniers mois, essentiellement à cause de deux articles controversés, peut-il être conclu entre toutes les parties d’ici la fin de l’année ? Oui, répond en substance l’Autriche, selon le journaliste Alexander Fanta. Le pays préside actuellement le Conseil de l’Union européenne, jusqu’au 31 décembre 2018.
Depuis le 12 septembre, date à laquelle le Parlement européen a approuvé à une large majorité la directive Copyright, une nouvelle séquence institutionnelle est ouverte : celles des trilogues. Il s’agit de réunions tripartites entre les trois grandes instances du Vieux Continent, à savoir le Parlement, le Conseil et la Commission.
Le fait est que l’échéance fixée par l’Autriche, qui laisse donc onze semaines aux parties pour se mettre d’accord, demeure relativement incertaine, même si Bruxelles est sur la même longueur d’onde : « La Commission est prête à travailler […] afin que la directive puisse être approuvée dès que possible, idéalement d’ici la fin de 2018 », déclarait en septembre Mariya Gabriel, la commissaire en charge de l’économie et la société numériques.
Ainsi, même si Gernot Blümel, le ministre responsable des relations européennes, de l’art, de la culture et des médias dans le gouvernement autrichien, affirme que son pays « fera de son mieux » pour boucler ce dossier pendant sa présidence, des dissensions se font jour entre les États membres eux-mêmes.
La journaliste Laura Kayali rapportait début octobre que l’Italie a officialisé, lors d’une réunion avec des diplomates, le retrait de son soutien à l’égard de la directive sur le droit d’auteur. Il ne s’agit toutefois pas d’une totale surprise, puisque la position de Rome, qui a fait un 180° à la suite de la mise en place du nouveau gouvernement populiste, sur ce sujet avait déjà été exprimée au cours de l’été.
Prochaine réunion fin octobre
Selon l’eurodéputée Julia Reda, très impliquée sur ce dossier, le prochain trilogue doit avoir lieu le 25 octobre. Outre les articles controversés, qui concerne respectivement la création d’un droit voisin pour la presse sur le web et le filtrage automatique des contenus mis en ligne, il sera question des exceptions au droit d’auteur concernant la fouilles de textes (text data mining) l’enseignement et la préservation par les institutions du patrimoine culturel ou encore les droits d’auteur.
Un outil en ligne, disponible seulement en anglais, permet par ailleurs de comparer les positions du Conseil, du Parlement et de la Commission sur chaque article de la directive sur le droit d’auteur.
En admettant qu’un accord soit trouvé, celui-ci devra faire l’objet d’un vote final au niveau du Parlement européen. C’est d’ailleurs sur ce scrutin que les opposants au texte vont se positionner pour tenter de faire bouger les lignes politiques et convaincre une majorité de parlementaires de s’opposer au texte — et ainsi rééditer l’exploit de 2012 avec le rejet du projet d’accord commercial anti-contrefaçon (ACTA).
Si le Parlement européen ne s’y oppose pas, alors la transposition du texte dans le droit national commencera : la France a en effet l’obligation de le faire, dans un délai de quelques années. Une directive n’est pas d’application immédiate, contrairement à un règlement (le RGPD en est l’illustration). En outre, la directive laisse aux États une certaine appréciation sur la façon de satisfaire les objectifs du texte.
L’association française Framasoft se bat pour proposer un maximum de variations «libres» des principaux services commerciaux de Microsoft, Google et même Facebook. Son but: se libérer du joug de ces géants de la technologie
Microsoft vient de suspendre la mise à jour de Windows 10, à cause des problèmes rencontrés par ses utilisateurs.
(CCM) — Le déploiement de la mise à jour de Windows 10 est suspendu jusqu'à nouvel ordre. Microsoft plie face aux nombreuses réactions négatives des utilisateurs de l'October Update. Certains ont vu leurs données personnelles disparaître à cause de la mise à jour d'octobre.
Cela faisait moins d'une semaine que le déploiement avait été lancé. Mais très rapidement, la mise à jour de Windows 10 a commencé à poser problème. Notamment, des problèmes de compatibilité sont apparus entre la nouvelle version de l'OS et certains processeurs Intel non mis à jour. Résultat : des problèmes de consommation de ressources, ou la suppression de fichiers vidéos, audio ou images.
D'autres utilisateurs ont également rapporté avoir retrouvé sur OneDrive (dans le cloud) des données qu'ils n'avaient pas envoyées eux-mêmes. Et certains cas de disparition pure et simple de données personnelles sont même apparus. Devant tant d'interrogations, le support de Microsoft a annoncé la suspension de de la mise à jour October Update. Sans doute dans l'attente qu'une nouvelle version soit compilée et mise à disposition de tous les possesseurs de Windows 10.
Le Canard Enchaîné consacre son hors-série Les dossiers du Canard d'octobre 2018 à la question de la vie privée. Le journal revient à cette occasion sur l'emprise de Microsoft sur les ministères français, en particulier celui des Armées où le géant américain impose ses systèmes via un accord Open Bar renouvelé deux fois depuis 2009.
Pantouflage, marchés publics opaques, rapports opposés au contrat, enjeux de souveraineté et de sécurité, le Canard rappelle sur deux pages l'accumulation de couacs concernant l'Open Bar Microsoft au ministère des Armées. Une situation de dépendance que seule une commission d'enquête parlementaire, demandée par la Sénatrice Joëlle Garriaud-Maylam, Secrétaire de la commission des affaires étrangères, de la défense et des forces armées, depuis octobre 2017 et que l'April appelle à soutenir, pourra permettre d'adresser.
Comme le rappelle Frédéric Couchet, délégué général de l'April, interviewé pour cet article, « il est clair qu'il y a eu une commande politique de signer avec Microsoft malgré les rapports négatifs ». Il est indispensable que le Parlement joue son rôle de contrôle de l'action gouvernementale. Un constat sans appel après plusieurs années d'action de l'association pour que lumière soit faite sur ce dossier.
L'April a consacré une partie de sa première émission Libre à vous ! de mai 2018 à l'Open Bar, afin d'en expliquer les enjeux, les dangers et les parts d'ombre. Nous étions en compagnie de la sénatrice Joëlle Garriaud-Maylam et de Marc Rees, rédacteur en chef de Next INpact. Un podcast est disponible pour (ré)écouter ce segment de l'émission, ainsi qu'une transcription à (re)lire.
Extrait de l'article
Lors d'un déplacement le 1er octobre 2018 à la Direction interarmées des réseaux d'infrastructure et des systèmes d'information (DIRISI), la ministre de l'Armée Florence Parly a « appelé à une plus grande ouverture du ministère aux logiciels libres et annoncé que Qwant, moteur de recherche français qui s'engage à ne pas exploiter les données personnelles de ses utilisateurs, serait désormais le moteur de recherche par défaut du ministère des Armées. »
Recommandation qui aurait dû être suivie depuis longtemps : le ministère dispose depuis 2006 d'un rapport préconisant une migration vers le logiciel libre. L'April rappelle enfin qu'une « ouverture vers le logiciel libre » ne pourra réellement s'opérer sans une véritable politique de désintoxication du ministère aux logiciels Microsoft.